视觉SLAM学习笔记:七
第九、十章
后端
贝叶斯公式
在正式开始之前,需要复习一下贝叶斯公式,基本的形式是
$$P(X | Y)=\frac{P(XY)}{P(Y)}$$之后需要用到一个进阶的式子:$$P(A|B,C)=\frac{P(B|A,C) \cdot P(A|C)}{P(B|C)}$$
下面来证明这个式子:
首先假设事件$D$:已知$C$
然后得到:$$P(A|B,C)=P(A|B,D)$$
把$BD$看作整体,使用最基础的贝叶斯公式,得到:$$P(A|B,D)=\frac{P(B,D|A) \cdot P(A)}{P(B,D)}$$
现在把$D$换回$C$,唯一需要特殊处理的是分子的第二项:$P(A)$,这里有个技巧,就是在整个推导过程中,$C$始终是已知的背景,所以$P(A)$其实隐含了“在已知$C$的前提下”,所以应该写为$P(A|C)$,或者从另一种视角来看,在机器人模型中,一般认为$C$(历史信息)和$A$(当前状态)是独立的,同样可以得到$P(A)=P(A|C)$
综上,式子变为:$$P(A|B,C)=\frac{P(B,C|A) \cdot P(A|C) }{P(B,C)}$$
对分母使用贝叶斯公式,得到:$$P(A|B,C)=\frac{P(B,C|A) \cdot P(A|C) }{P(B|C) \cdot P(C)}$$
分子的第一项可以展开为:$$P(B,C|A)=P(B|C,A) \cdot P(C|A)$$
这个式子等最后证明
又因为一般假设$C$与$A$无关,或者说当前状态不会影响历史信息,所以$P(C|A)=P(C)$
然后就得到了:$$P(A|B,C)=\frac{P(B|C,A) \cdot P(C) \cdot P(A|C)}{P(B|C) \cdot P(C)}=\frac{P(B|C,A) \cdot P(A|C)}{P(B|C)}$$
至此,证毕。等下使用概率推导的时候就直接使用了。
然后把刚才的$P(B,C|A)=P(B|C,A) \cdot P(C|A)$证明一下。
对左边使用基础的贝叶斯公式,得到:$$P(B,C|A)=\frac{P(ABC)}{P(A)}$$
对右边使用贝叶斯公式,得到:$$P(B|C,A) \cdot P(C|A)=\frac{P(ABC)}{P(AC)} \cdot \frac{P(AC)}{P(A)}=\frac{P(ABC)}{P(A)}$$
左边=右边,得证。
KF
状态估计的概率解释

运动方程和观测方程的基本内容直接摘抄下来了
下面主要是推导概率公式,利用式(9.4),$P(x_{k}|x_{0},u_{1:k},z_{1:k})$
利用公式:$$P(A|B,C)=\frac{P(B|A,C) \cdot P(A|C)}{P(B|C)}$$
这里的$A$就是$x_{k}$,$B$是$z_{k}$
得到:$$P(x_{k}|x_{0},u_{1:k},z_{1:k})=\frac{P(z_{k}|x_{k},x_{0},u_{1:k},z_{1:k-1}) \cdot P(x_{k}|x_{0},u_{1:k},z_{1:k-1})}{P(z_{k}|x_{0},u_{1:k},z_{1:k-1})}$$
对于分子的第一项,还有一个假设,认为“当前观测只依赖当前状态”,得到:$$P(z_{k}|x_{k},x_{0},u_{1:k},z_{1:k-1})=P(z_{k}|x_{k})$$
还有,分母与$x_{k}$无关,可以看作“常数”,可写为:$$P(x_{k}|x_{0},u_{1:k},z_{1:k}) \propto P(z_{k}|x_{k}) \cdot P(x_{k}|x_{0},u_{1:k},z_{1:k-1})$$
第一项为似然,第二项为先验
先验部分的$x_{k}$是基于过去所有的状态估计得来的,至少会受到$x_{k-1}$的影响,以$x_{k-1}$时刻为条件概率展开得到:$$P(x_{k}|x_{0},u_{1:k},z_{1:k-1})= \int P(x_{k}|x_{k-1},x_{0},u_{1:k},z_{1:k-1}) P(x_{k-1}|x_{0},u_{1:k},z_{1:k-1})dx_{k-1}$$
第二项还可以继续往下展开,比如:$$P(x_{k-1}|x_{0},u_{1:k},z_{1:k-1})= \int P(x_{k-1}|x_{k-2},x_{0},u_{1:k},z_{1:k-1}) P(x_{k-2}|x_{0},u_{1:k},z_{1:k-1})dx_{k-2}$$
这里展开使用的公式是连续型的全概率公式:$$P(A)=\int P(AB)dB$$
再根据条件概率公式$P(AB)=P(A|B)P(B)$,得到:$$P(A)=\int P(A|B) P(B) dB$$
在这个式子中,$A$就是$x_{k}$
为了简化,把$x_{0},u_{1:k},z_{1:k-1}$记为$D$
即:$$P(x_{k}|D)=\int P(x_{k},x_{k-1}|D)dx_{k-1}=\int P(x_{k}|x_{k-1},D) P(x_{k-1}|D)dx_{k-1}$$
把$D$替换掉就是上面的式子。
到此为止,我们就把概率的基础部分推导完毕了,下面将根据不同的处理方法分为滤波器方法和非线性优化方法。具体如下:
KF与EKF
这部分内容书中给的足够详细了,再过于深入的数学推导以我现在的水平学习起来还非常困难,所以看完就过了。
这里贴一个线性KF的求解过程(具体推导略过),分为“预测”和更新“两步”,其中$\;\; \hat{}\;\;$表示后验概率,$\;\; \check{} \;\;$表示先验概率。
这是线性KF的总结,其中核心就是那个$K$,也就是卡尔曼增益,在(9.26)式中可以看出来,这个增益越大,那么$z_{k}$前的系数也就越大,即给观测的权重更大;反之,如果预测很准,即$\hat{P}_{k}$小,根据式(9.25),则$K$变小,那么$z_{k}$的权重就减小,$\check{x}_{k}$的权重就增大,就是说更加信任预测值。
然后再把EKF的结果贴上来,EKF就是拓展卡尔曼滤波,用于解决非线性问题,实际中SLAM中的运动和观测方程通常是非线性函数,把KF变为EKF通常做法是,在某个点附近考虑运动方程及观测方程的一阶泰勒展开,只保留一阶项,即线性的部分,然后按照线性系统进行推导。
下面就直接摘抄书中的内容,泰勒展开还是好理解的,通过运动方程得到先验和协方差也好说,但是后面推导卡尔曼增益和后验概率就不太会了,这里直接摘抄书上的结果。不管怎么说,作者也说了滤波器不好用,非线性优化才是主流,这里也就不再深究原理了。
首先是令$k-1$时刻的均值和协方差矩阵为$\hat{x}_{k-1},\hat{P}_{k-1}$,在$k$时刻,把运动方程和观测方程在$\hat{x}_{k-1},\hat{P}_{k-1}$处进行线性化(一阶泰勒展开),得到:$$x_{k} \approx f(\hat{x}_{k-1},u_{k})+\frac{\partial f}{\partial x_{k-1}}|_{\hat{x}_{k-1}}(x_{k-1}-\hat{x}_{k-1})+w_{k}$$
$$z_{k} \approx h(\check{x}_{k})+\frac{\partial h}{\partial x_{k}}|_{\check{x}_{k}}(x_{k}-\check{x}_{k})+n_{k}$$然后分别记两个偏导数为:$$F=\frac{\partial f}{\partial x_{k-1}}|_{\hat{x}_{k-1}}\;\;\;\;\;H=\frac{\partial h}{\partial x_{k}}|_{\check{x}_{k}}$$
在预测步骤中,根据运动方程有:$$P(x_{k}|x_{0},u_{1:k},z_{0:k-1})=N(f(\hat{x}_{k-1},u_{k}),F \hat{P}_{k-1} F^{T}+R_{k})$$
记先验和协方差的均值为:$$\check{x}_{k}=f(\hat{x}_{k-1},u_{k}),\;\;\;\;\; \check{P}_{k}=F \hat{P}_{k-1}F^{T}+R_{k}$$
然后是更新,有卡尔曼增益和后验概率,得到:$$K=\check{P}_{k}H^{T}(H \check{P}_{k} H^{T}+Q_{k})^{-1}$$
这就是EKF的结果,下面关于EKF的讨论也贴到这里,保持一个完整性
非线性优化
BA与图优化
这部分内容虽然长,但是读下来还是很好理解的,讲解比较细致,这里就不再详细写了,(实在没时间了,还得写报告,现在报告写什么还没想好)
滑动窗口优化
为了控制BA的规模,BA规模太大不能满足实时计算的要求,不适用于大规模场景,所以使用滑动窗口,最简单的是仅保留离当前时刻最近的$N$个关键帧,去掉时间上更早上关键帧,这就是滑动窗口法。
或者采用共视图的方法,即“与现在的相机存在共同观测的关键帧构成的图”,例如:仅优化与当前帧有20个以上共视路标的关键帧,其余部分固定不变。这些帧不见得在时间上是最近的,而大概是时间上靠近,而空间上有可以展开的关键帧。
书上这部分只有一些理论推导,没有实践部分,由于时间问题,这里我仅把直观的理解图贴到这里,具体理论书中说的很明白。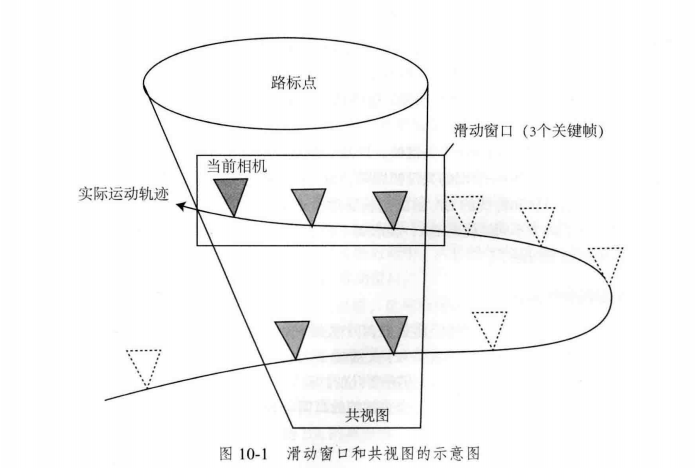
位姿图
目前重点还是在概念理解部分,如下: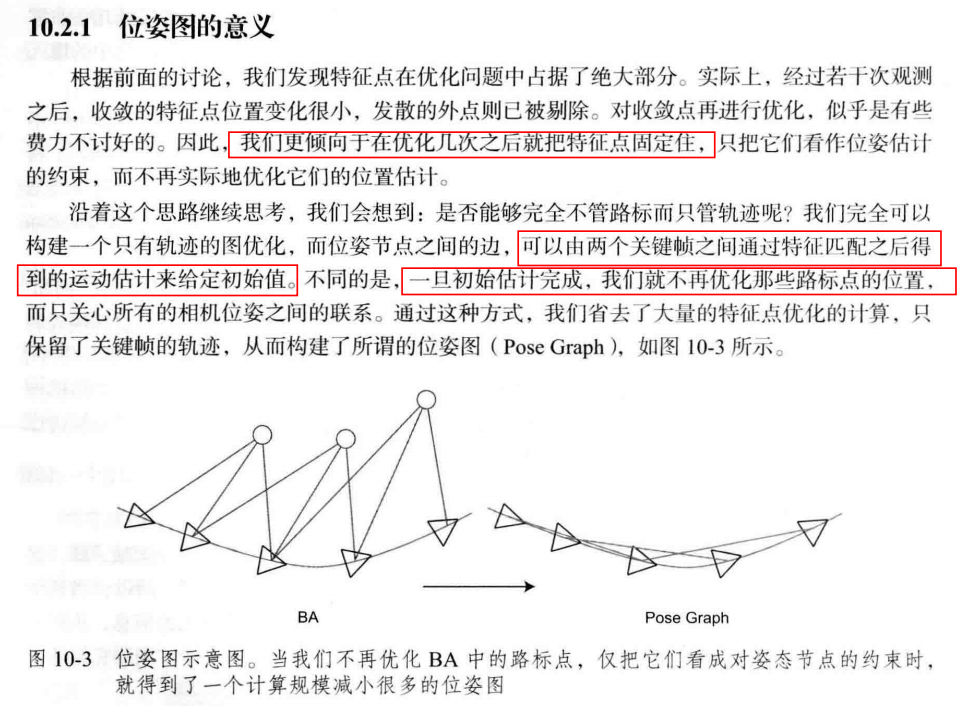
至于位姿图的理论推导,我确实是没看懂,过了伴随性质就看不懂了,其实误差怎么构建出来的也不明白,但至少能看出来:如果等式成立,那么误差为0,起码基本的逻辑是对的。
这里为了加快速度,就把理论的部分跳过了,等到实践过后可能会有更好的理解
不管怎么说,终究是是一个最小二乘问题,最后还是使用非线性优化的方法来解决。
后端说到底还是要优化前端给的一个初始值,构建了一个尺度、规模更大的优化问题,以考虑长时间的最优轨迹和地图。就算具体内容不理解,整体方向也得把握住。
到此为止,后端的内容就告一段落了。